十来天前写过一篇 Redis 之前如何用 曲线救国 的方式用作消息队列 “使用 Redis 作为消息队列 - Pub/Sub, List, SortedSet“,只能说简单的使用方式勉强还行,离真正意义上的消息队列有些距离。而自 Redis 5.0 加入了 Stream 就更进一步,可望朝着作为正规消息队列的 At most once, At least once, 和 Exactly once 方向迈进。
如果以 Serverless 方式使用 AWS 的 Redis, 那么既然用到高级消息队列的功能,还能省去使用 AmazonMQ(ActiveMQ 或 RabbitMQ) 或 MSK(Kafka) 的高成本。
Redis stream 数据结构像是一个 append-only 日志,但又添加了 O(1) 的随机访问和复杂的消费策略,如消息分组。
Redis Stream 的每条消息会有一个唯一 ID, 支持消费组, Redis 用以支持 Stream 的一系列命令是 X 为前缀的,点击 这里 查看完整的 Stream 命令列表。
用 Docker 在本地启动一个 Redis
> $ docker run -it -p 6379:6379 redis:7.2
XADD 生产一条消息
> 127.0.0.1:6379> xadd tasks * id 1000 action update
> "1724274492422-0"
> 127.0.0.1:6379> xadd tasks * id 1001 action delete
> "1724274510004-0"
> 127.0.0.1:6379> keys *
> 1) "tasks"
- 用
*指示让 Redis 自动产生消息 ID,格式是<timestamp-in-ms>-<seq>, 多条消息在同一时刻,序号递增,所以一般 seq 是0。我们也可以指定 ID, 基本没必要这么做。XADD不允许用重复的 ID。Redis 7 开始可只指定ID的前部分,后部自增,如xadd tasks 0-* value "{}" - stream 就是 Redis 的一个 key, 如这里的
tasks - 消息内容可以定义为简单的键值对,意义也不大。如果消息中稍有嵌套层次就无法表示,还不如就用一个
field,值为 json 字符串,如127.0.0.1:6379> xadd tasks * value "{\"id\": 1000, \"action\":\"update\"}" "1705383464254-0"
XADD 添加的每条消息都有一个 ID, 和 ZADD 添加记录时带一个 Score 值差不多,下面用 XRANGE 和 XREAD 读取消息
XRANGE 的最基本的用法是 XRANGE key start end [COUNT count]
127.0.0.1:6379> xrange tasks 1724274492422-0 1724274510004-0 count 2
1) 1) "1724274492422-0"
2) 1) "id"
2) "1000"
3) "action"
4) "update"
2) 1) "1724274510004-0"
2) 1) "id"
2) "1001"
3) "action"
4) "delete"
在表示 start, end 时有一些特殊表示法,如 -, + 分别表示最小最大的 ID,( start 值大于相应的值,后面还有别的特殊的 ID,如 >, $, *
xrange tasks - + count 10# 所有范围xrange tasks (1724274492422-0 + count 10# 目的是为了排除自己, 相当于从 1724274492422-0-1 开始xrange tasks 1724274492422-0 1724274510004-0#只取指定的 ID 对应数据xrange task 1724274492422 1724274510004-0# 不完整的 ID 值,左边会附加-0, 右边附加-18446744073709551615, 即各自扩充到边界
XREAD 的用法是 XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
XREAD 有阻塞模式和同步模式,指定 BLOCK 就会等待有消息或时间到为止,同步模式类似于的 XRANGE,但略有不同
xread count 100 block 300 streams task 1724274492422-0# 阻塞方式从大于 1724274492422-0 之后读取,有消息立即返回,无消息则直等到 300 毫秒为止,最多返回消息 100 条xread count 2 streams tasks news 0-0 1724274510004# 读取 tasks 中 ID 大于 0-0 后的消息和 tasks 中 ID大于 1724274510004 之后的消息xread streams tasks 1705383436204-0# 读取 tasks 中 ID 大于 1705383436204-0 之后的消息,相当于 xrange tasks (1705383436204-0 +xread block 5000 streams tasks $# 特殊的 $ID 表示当前最大 ID, 相当于xread streams tasks <LAST_ID>, 即读取启动客户端时最新的消息,又像是tail -f logfile操作
现在无论是用 xrange 还是 xread, 取得消息之后,它们仍然在 Redis 当中,并没有 pop 出来,我们可主动用 xdel 根据 ID 来删除消息。但是从目前的 XADD、XRANGE、XREAD、XDEL 使用上来看,还无法防止消息被重复消费,因为连一个 POP 行为都没有,所以还不如 SortedSet 的 ZADD、ZRANGEBYSCORE、ZPOPMIN 高明,不过别急,好戏还在后头。
其实本人最关心的是 Redis Stream 怎么能像 Kafka 或 SQS 一样进行消费分组。首先简单回顾一下 Kafka 和 SQS 处理方式
Kafka 的处理方式,用一张图来表示会好理解些
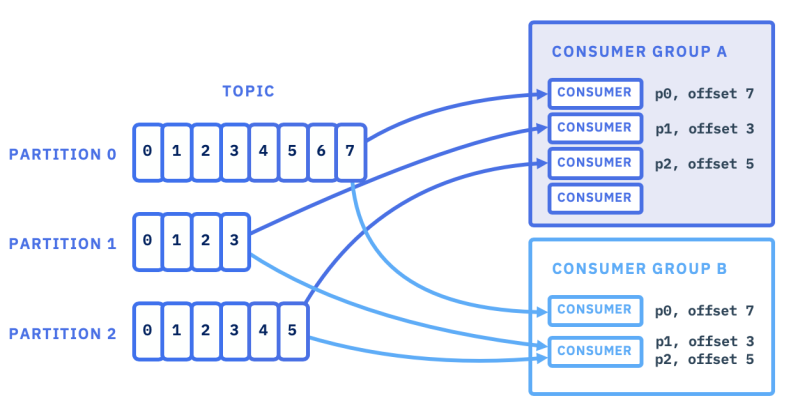
AWS SQS 从一定意义上来说也是支持 Consumer Group 的,一个 Topic 只支持一个消费组,它的实现是某个消息被某个客户端取走后,状态变成了 In-Flight,对其他客户端不可见。消息取得后必须在特定的 Invisibility timeout 期间处理完消息并从队列中删除,或在 Invisibility Timeout 到期后消息又对其他客户端可见。以此避免了同一消息不被多个客户端重复消费,还能实现消息的重试。
消费组
例如对于监听同一个 stream 的三个消费者 C1、C2、C3, 发往该 stream 的消息 1、2、3、4、5、6、7 希望分别路由到不同的消费者:
1 -> C1
2 -> C2
3 -> C3
4 -> C1
5 -> C2
6 -> C3
7 -> C1
这一看就是个 Round-Robin 算法。
Redis Stream 的 Consumer Group 借鉴了 Kafka 的实现:
- Consumer Group 有一个唯一标识,同一个消费组中,每一个消费者必须要有一个唯一的标识,当该消费者断开重连后,还能由此找回上次的状态继续。
- 每一个 Consumer Group 要记住最后一个未消费消息的 ID, 相当于 Kafka 的 Offset。
- 消息消费后需要被显式的确认,说该消息已被正确处理,可从当前 Consumer Group 中驱除(消息仍然在 Redis 中)。
- 一个 Consumer Group 要跟踪每一个正在处理中(pending),但未确认的消息。
- 单个 stream 可以含多个 Consumer Group, 消息在一个组类只会被消费一次。
用下面的文字来描述 Consumer Group 以及其中的 Consumer 就很容易理解:
+----------------------------------------+
| consumer_group_name: mygroup |
| consumer_group_stream: somekey |
| last_delivered_id: 1292309234234-92 |
| |
| consumers: |
| "consumer-1" with pending messages |
| 1292309234234-4 |
| 1292309234232-8 |
| "consumer-42" with pending messages |
| ... (and so forth) |
+----------------------------------------+
Redis 的单个 Stream 也可以有多个 Consumer Group,与 Consumer Grouper 有关的命令如下:
- XGROUP: 用来创建,销毁和管理 Consumer Group。
- XREADGROUP: 通过 Consumer Group 来从 Stream 中读取消息。
- XACK: 让消费者标记 pending 状态的消息为已处理。
Redis 需要手工预先创建 Consumer group, 可为一个 stream 创建多个 Consumer Group。
127.0.0.1:6379> xgroup create tasks consumer_group_1 $
OK
127.0.0.1:6379> xgroup create tasks consumer_group_2 $
OK
Stream(key) tasks 必须已存在,如果 tasks 不存也可加上 MKSTREAM 自动创建该 key。
127.0.0.1:6379> xgroup create any_key consumer_group_1 $ MKSTREAM
OK
127.0.0.1:6379> keys *
1) "tasks"
2) "any_key"
any_key 不存在的话,则会自动创建。
创建消费组时必须指定下一次从哪个 ID 之后开始消费, $ 代表当前最大 ID,表示该 consumer_group_1 创建后只消息新消息,当然可以指定 ID, 如 0, 或实际存在的 ID, 表示从其后开始消费。
XREADGROUP
除了要指定 consumer group 名称以及自身 consumer 名称,其他参数与 XREAD 是一样的,也有阻塞模式与同步模式。
在我们前面创建两个消费组 consumer_group_1 和 consumer_group_2 之后,在另一个 Redis CLI 窗口执行。
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_1 count 1 streams tasks >
(nil)
没有消息,但我们用 xadd 加入一条消息之后:
127.0.0.1:6379> xadd tasks * id 1002 action add
"1724275995354-0"
再用不同的 Consumer Group 和 Consumer 来取消息:
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_1 count 1 streams tasks >
1) 1) "tasks"
2) 1) 1) "1724275995354-0"
2) 1) "id"
2) "1002"
3) "action"
4) "add"
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_1 count 1 streams tasks >
(nil)
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_2 count 1 streams tasks >
(nil)
127.0.0.1:6379> xreadgroup group consumer_group_2 consumer_1 count 1 streams tasks >
1) 1) "tasks"
2) 1) 1) "1724275995354-0"
2) 1) "id"
2) "1002"
3) "action"
4) "add"
127.0.0.1:6379> xreadgroup group consumer_group_3 consumer_1 count 3 streams tasks >
(error) NOGROUP No such key 'tasks' or consumer group 'consumer_group_3' in XREADGROUP with GROUP option
xreadgroup 要指定消费组与消费者名称,消费者会自动创建,如上面的 consumer_group_1 和 consumer_1。我们看到在同一个消费组内被消费的消息不能再被同组内其他消费者消费,而在别的消费组内还能再次被消费。且只能使用已创建好的 Consumer Group, 但组类的 Consumer 名称可以随意指定,新名称即为组内新的消费者,比如在一集群中每个节点可以用本机的 IP 地址作为 Consumer 的名称,IP 地址被新节点重用时那就姑且让它顶替原来的 Consumer 工作吧。
xreadgroup 获取到消息后会更新消费组的 last ID, 所以下次再用 > 也取不到刚才的消息,所以 xreadgroup 是一个写命令,只能在 Master 节点上执行。
如果 xreadgroup > 处指定了任何数字 ID,就会取出它之后的所有 pending 的但未用 XACK 确认过的消息:
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_1 count 3 streams tasks 123
1) 1) "tasks"
2) 1) 1) "1724275758708-0"
2) 1) "id"
2) "1001"
3) "action"
4) "delete"
2) 1) "1724275995354-0"
2) 1) "id"
2) "1002"
3) "action"
4) "add"
xreadgroup group consumer_group_1 consumer_1 count 3 streams tasks 123 执行多次都可以取得相同的这两条消息,说明消息处于 Pending 状态,未被确认。
xack 命令用于在组上确认消息已处理,下次在该组内不会再收到该消息了:
127.0.0.1:6379> xack tasks consumer_group_1 1724275995354-0
(integer) 1
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_1 count 3 streams tasks 123
1) 1) "tasks"
2) 1) 1) "1724275758708-0"
2) 1) "id"
2) "1001"
3) "action"
4) "delete"
127.0.0.1:6379> xreadgroup group consumer_group_2 consumer_1 count 3 streams tasks 123
1) 1) "tasks"
2) 1) 1) "1724275758708-0"
2) 1) "id"
2) "1001"
3) "action"
4) "delete"
2) 1) "1724275995354-0"
2) 1) "id"
2) "1002"
3) "action"
4) "add"
127.0.0.1:6379> xack tasks consumer_group_2 1724275758708-0 1724275995354-0
(integer) 2
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_1 count 3 streams tasks 123
1) 1) "tasks"
2) 1) 1) "1724275758708-0"
2) 1) "id"
2) "1001"
3) "action"
4) "delete"
127.0.0.1:6379> xreadgroup group consumer_group_2 consumer_1 count 3 streams tasks 123
1) 1) "tasks"
2) (empty array)
从上面我们可以观察到消息只在消费组内确认,不影响其他消费组。
- 消息在消费组内确认后,对当前消费组内的所有消息者不可见了,不是 Pending 状态,而可以认为是被清除了。
- 消息在消费组内确认后,不影响在其他消费组中的状态。
现在我们对于 Redis Stream 实现消息队列,分组消费有了一个基本了解后,也得到了实现了一分组消费消息队列的基本元素。
- 消息在一个消费组内应该只被某一个消费者消费一次(避免读取到已经 Pending 状态的消息)。
- 消费组内确认的消息在当前组内不可见,但不影响别的消费组。
- 消费处理完后可以当前消费组内进行确认,以便于继续处理后续的消息。
我们开始作一个 Consumer Group 的演示。把 Redis 官方的 Ruby 翻译成 Python 代码 test_redis.py,需用 pip install redis 依赖
import redis
import sys
group_name = sys.argv[1]
consumer_name = sys.argv[2]
stream = 'tasks'
r = redis.Redis()
def process_message(msg_id, msg):
print(f"[{consumer_name}] {msg_id} = {msg}")
last_id = '0-0'
print(f"Consumer {group_name}[{consumer_name}] starting...")
check_backlog = True
while True:
if check_backlog:
my_id = last_id
else:
my_id = '>'
items = r.xreadgroup(group_name, consumer_name, {stream: my_id}, count=10, block=2000)
if items is None:
print("Timeout!")
continue
check_backlog = items and items[0][1]
for item in (items[0][1] if items else []):
msg_id, fields = item
# 处理消息
process_message(msg_id, fields)
# ACK 消息
r.xack(stream, group_name, msg_id)
last_id = msg_id
下图是测试的效果:
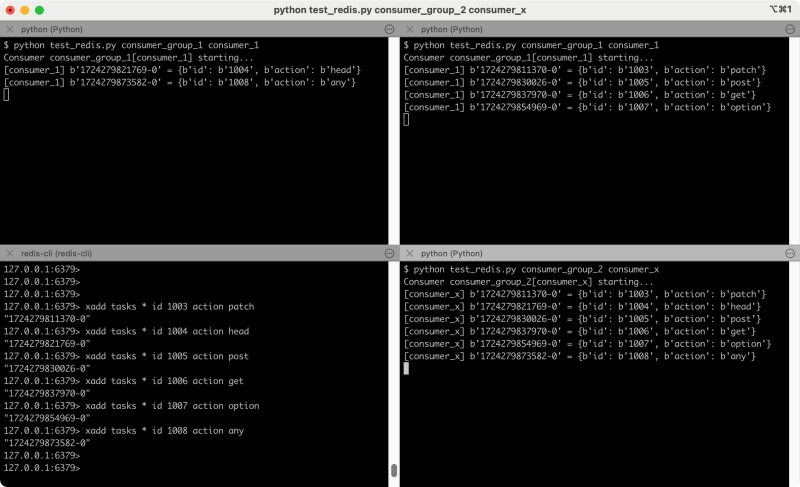
在终端的 左上,右上,右下分别运行的命令是:
- 左上:python test_redis.py consumer_group_1 consumer_1
- 右上:python test_redis.py consumer_group_1 consumer_2
- 右下:python test_redis.py consumer_group_2 consumer_x
在左下往 Stream 中发送消息,共发送了 6 条消息
- 在消费组 consumer_group_1 下启动了两个消费者,其中 consumer_1 消费了 2 条,consumer_2 中消费了 4 条,分布不那么均匀。
- 在消费组 consumer_group_2 下只有一个消费者 consumer_x。
有了以上的 xadd、xrange、xread、xreadgroup、xack 命令,我们就可以完全实现一个现代的基于消息的服务系统了。
再有其他几个 X 命令是辅助性的,如 xpending、xpending_range、xclaim、xautoclaim
xpending
当 xadd 添加的记录用 xreadgroup 以某个 consumer 取出后未被 xack 确认之前,消息的状态是 pending 的,没有确认或 claim 的话消息一直处于 pending 并期待老的 consumer 来消费它。xclaim 可让消息释放出来给另一个 consumer 帮忙消费处理。看下面一系列的命令:
127.0.0.1:6379> xpending tasks consumer_group_1 // 没有 pending 的消息
1) (integer) 0
2) (nil)
3) (nil)
4) (nil)
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_1 count 2 streams tasks 123
1) 1) "tasks"
2) (empty array)
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_1 count 1 streams tasks >
(nil)
127.0.0.1:6379> xadd tasks * id 1000 action update
"1724291071862-0"
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_1 count 1 streams tasks > // 添加一条消息条,取出来
1) 1) "tasks"
2) 1) 1) "1724291071862-0"
2) 1) "id"
2) "1000"
3) "action"
4) "update"
127.0.0.1:6379> xpending tasks consumer_group_1 // 前面取出来的消息状态就是 pending 的,并且与 consumer_1 相关联
1) (integer) 1
2) "1724291071862-0"
3) "1724291071862-0"
4) 1) 1) "consumer_1"
2) "1"
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_2 count 1 streams tasks 123 // 被 consumer_1 关联的 pending 消息对 consumer_2 不可见
1) 1) "tasks"
2) (empty array)
127.0.0.1:6379> xclaim tasks consumer_group_1 consumer_2 6000 1724291071862-0 // 声明可以让 consumer_2 来处理
1) 1) "1724291071862-0"
2) 1) "id"
2) "1000"
3) "action"
4) "update"
127.0.0.1:6379> xpending tasks consumer_group_1 // claim 后所有权转换到了 consumer_2
1) (integer) 1
2) "1724291071862-0"
3) "1724291071862-0"
4) 1) 1) "consumer_2"
2) "1"
127.0.0.1:6379> xreadgroup group consumer_group_1 consumer_2 count 1 streams tasks 123 // 这时候 consumer_2 可以获得该记录
1) 1) "tasks"
2) 1) 1) "1724291071862-0"
2) 1) "id"
2) "1000"
3) "action"
4) "update"
127.0.0.1:6379> xack tasks consumer_group_1 1724291071862-0 // 消息被 xack 确定后就不是 pending 状态
(integer) 1
127.0.0.1:6379> xpending tasks consumer_group_1
1) (integer) 0
2) (nil)
3) (nil)
4) (nil)
xclaim 实际上转移了消息所有权,让别的 consumer 可以读取来处理。xclaim 有点像 SQS 的消息 visibility(in-flight)超时后自动回退到队列中去, 这样别的消费者可以取到。
试想一下,如果集群中某个节点用 xreadgoup 取来消息正在处理当中被关闭了,那么未被 xack 确认的消息就变成了 pending 状态,这时候就需要有一个过程把 pending 状态的并被非活跃 consumer 占有的消息用 xclaim 释放给活跃 consumer,比如分配给自己,因为自身的 consumer 名称是可知的。多个节点同时 claim 一条记录也没关系,只有一个节点能 claim 成功。还有一个 xautoclaim 命令可指定 ID 范围,暂不清除具体作用与好处。xinfo consumers stream group 能列出活跃与非活跃的 consumer,如果 pending 状态的消息关联到一个活跃 consumer 就不要去 claim 它。
消息的 number of deliveries 计数会在 xclaim 和 xreadgroup 执行后自增,这能用来判定消息被处理了多少次,然后决定是否要继续还是丢弃或其他处理。这就像 SQS 的 Dead Letter Queue 的处理
xinfo stream、xinfo groups、xinfo consumers 可为我们监察 stream 相关的信息
stream 中的消息存太多了如何清除呢?我们在 xadd 添加消息的时候可以指定最多保留多少条记录,自动添除老的记录,如
xadd tasks maxlen 1000 * id 1000 action update # 最多保留 1000 条记录
xadd task maxlen ~ 1000 * id 1001 action add # 模糊的,至少 1000; 比如 1000, 1010 或 1030
xtrim 是有一样的效果,它是后处理的, 如 xtrim task maxlen 1000, xtrim 和 xadd 都可以根据 MINID 来清除旧记录,因为 ID 为时间截,我们在没有 TTL 设定的情况下可据此清除多久以前的记录。
总结:
- 消息可被多个消费组消费
- 消费者名称应科学选择,如用 IP 地址,重用了 IP 的机器启动后可以继续处理先前的 pending 状态消息
- 一个消费组可有多个消费者,一条消息只会被其中一个消费者消费
- 消费者以 PULL 的方式读取消息
- 组类的消费者有同等的机会获得消息
- 消息被某个消费都获后,状态变为 pending, 并且该消费者关联,对消费组内的其他消费者不可见
- 消费都用 XACK 命令来标记消息已被处理,并记录 Last ID
- XADD, XTRIM 可以通过最大消息数或最小消息 ID 来驱逐老的消息
- 因为消息处理过程中可能有异常(如关机),需适时检查 Pending 且关联了非活跃消费者的记录,进行 XCLAIM, XAUTOCLAIM 转移所有权。
参考链接: