关于多级排序,写过sql的朋友们都应该知道使用order by来使用,非常简单。抗日片手撕日本人,那么你能否手撕代码写出一个多级排序呢?
解题思路 :用过fork的朋友们,应该知道什么叫递归分支最后合并吧。那么我们的解题也是如此。
首先思考一下单次排序:单个排序很简单,根据排序的字段计算出一个分数,然后根据这个分数进行倒叙或者升序。
然后我们来思考一下多级排序的结果集特点:多级排序就是对数据进行多次单次排序,但与单次排序仍有部分差异,多级排序只有第一级排序与单词排序类似 ,然后第二级,第三级,均是根据上一个排序结果,通过相同的分数的数据,通过多个分数相同的结果,进行一个小范围的排序。此类排序,不会影响到第一次排序分数的排序,改变的只是,上一级相同分数的顺序。
我们能发现,其实多级排序的特点是,根据第一个排序字段排序完毕后,如果存在多条数据的排序分数一样,第二次排序就会根据这些多个范围,分数相同的小集合进行一个排序,第三次与第二次相同,都不会对第一次排序进行影响。
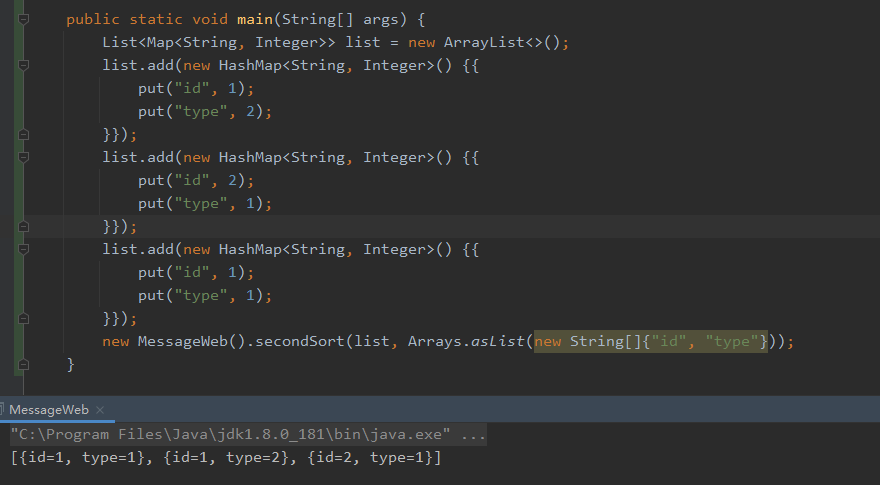
上述提到了,小范围相同数据的排序,那么本文就以二级排序作为示例,先上代码:
public void secondSort(List<Map<String, Integer>> notices, List<String> sort) {
// 第一次排序
Map<Integer, List<Map<String, Integer>>> collect = notices.stream().collect(Collectors.groupingBy(i -> i.get(sort.get(0))));
//第二次排序
ArrayList<Map.Entry<Integer, List<Map<String, Integer>>>> entries = new ArrayList<>(collect.entrySet());
entries.sort(Map.Entry.comparingByKey());
Map<Integer, List<Map.Entry<Integer, List<Map<String, Integer>>>>> sorts = new HashMap<>();
for (Map.Entry<Integer, List<Map<String, Integer>>> entry : entries) {
Map<Integer, List<Map<String, Integer>>> collect1 =
entry.getValue().stream().collect(Collectors.groupingBy(i -> i.get(sort.get(1))));
ArrayList<Map.Entry<Integer, List<Map<String, Integer>>>> entries1 = new ArrayList<>(collect1.entrySet());
entries1.sort(Map.Entry.comparingByKey());
sorts.put(entry.getKey(), entries1);
}
List<Map<String, Integer>> sortNotice = new ArrayList<>();
for (Map.Entry<Integer, List<Map.Entry<Integer, List<Map<String, Integer>>>>> integerListEntry : sorts.entrySet()) {
integerListEntry.getValue().stream().forEach(i -> sortNotice.addAll(i.getValue()));
}
System.out.println(sortNotice);
}
public static void main(String[] args) {
List<Map<String, Integer>> list = new ArrayList<>();
list.add(new HashMap<String, Integer>() {{
put("id", 1);
put("type", 2);
}});
list.add(new HashMap<String, Integer>() {{
put("id", 2);
put("type", 1);
}});
list.add(new HashMap<String, Integer>() {{
put("id", 1);
put("type", 1);
}});
new MessageWeb().secondSort(list, Arrays.asList(new String[]{"id", "type"}));
}