JMM了解
首先我们可以思考下JMM内存模型的提出是为了解决什么问题?
为什么会存在“内存可见性”问题
我们一起来看下,下图是一个x86架构下CPU的缓存布局。即在一个CPU 4核下,L1、L2、L3三级缓存与主内存的布局。从图中我们可以看到,每个核上都有L1、L2缓存,而L3缓存为所有核共有。
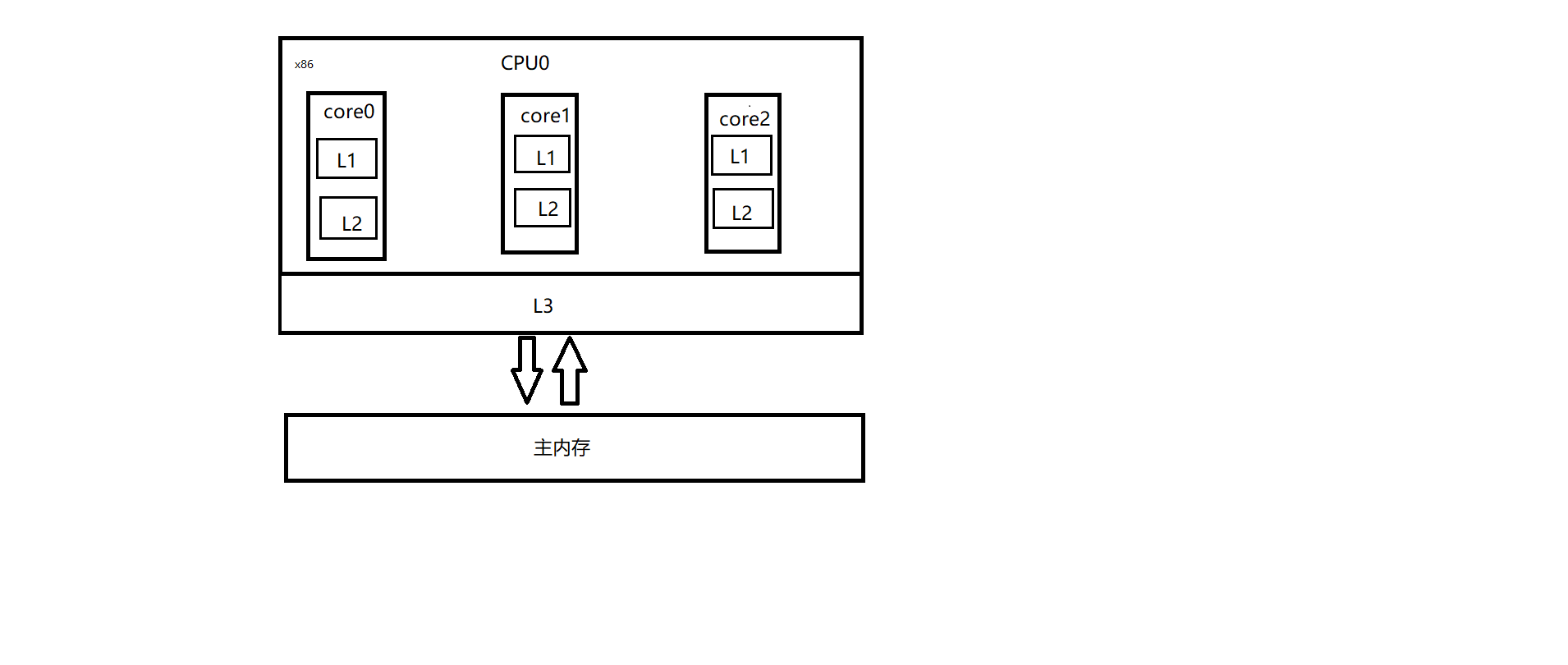
因为存在CPU缓存一致性协议,例如MESI,多个CPU核心之间的缓存不会出现不同步的问题,不会有“内存可见性”问题。
而缓存一致性协议要求我们多个CPU核心之间的缓存需要保持同步,那么同步就会带来性能问题,会损耗很大的性能。为了解决性能问题,前辈们又进行了各种优化。例如:在计算单元和L1之间加了Store Buffer、Load Buffer等。如下图:
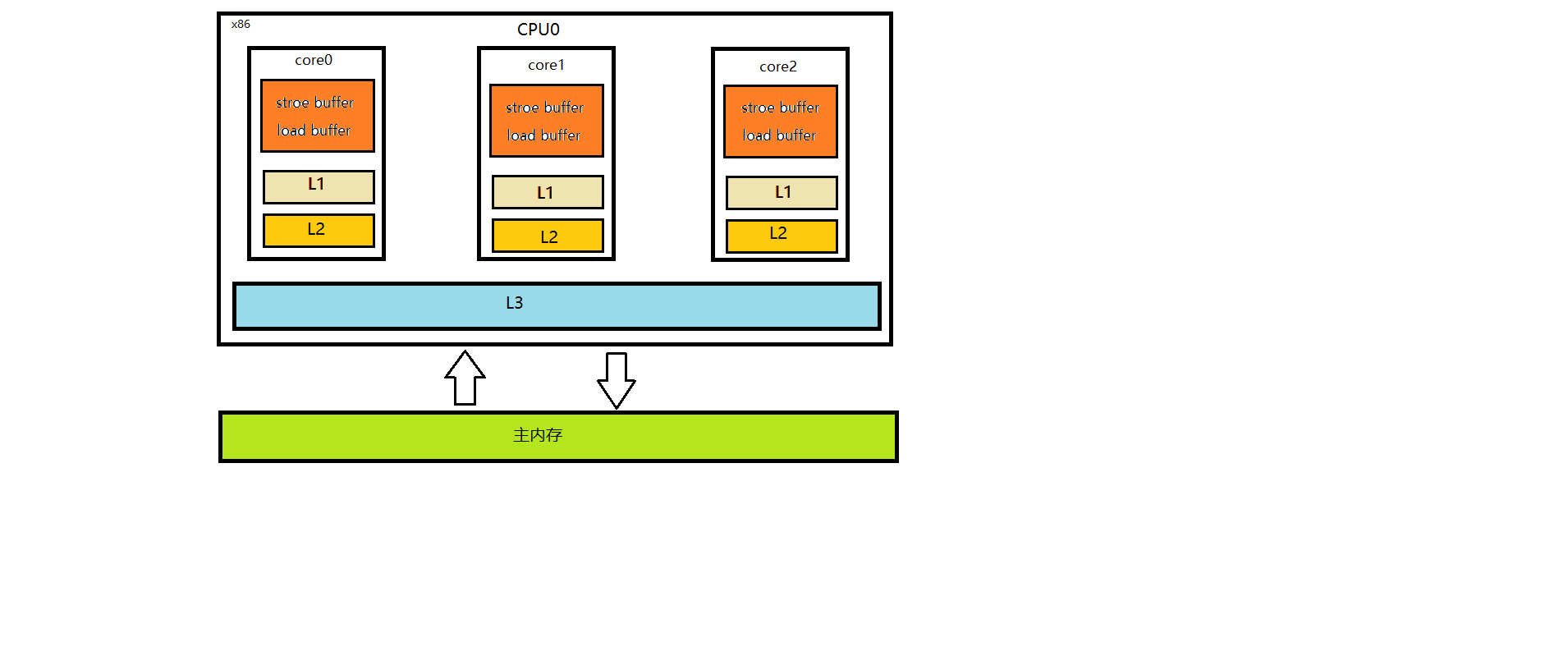
L1、L2、L3和主内存之间是同步的,有缓存一致性协议的保证,但是Store Buffer 、Load Buffer和L1之间却是异步的。当我们向内存中写入一个变量时,这个变量就会保存在Store Buffer里面,稍后才会异步的写入到L1中,同时同步的写入到主内存中。(这样的话就可能会出现有一部分数据是存在buffer里,有一部分存在缓存里,因为buffer中的数据是异步写入到L1内存中的,就会出现数据不一致的问题)。
我们从操作系统的角度去理解。
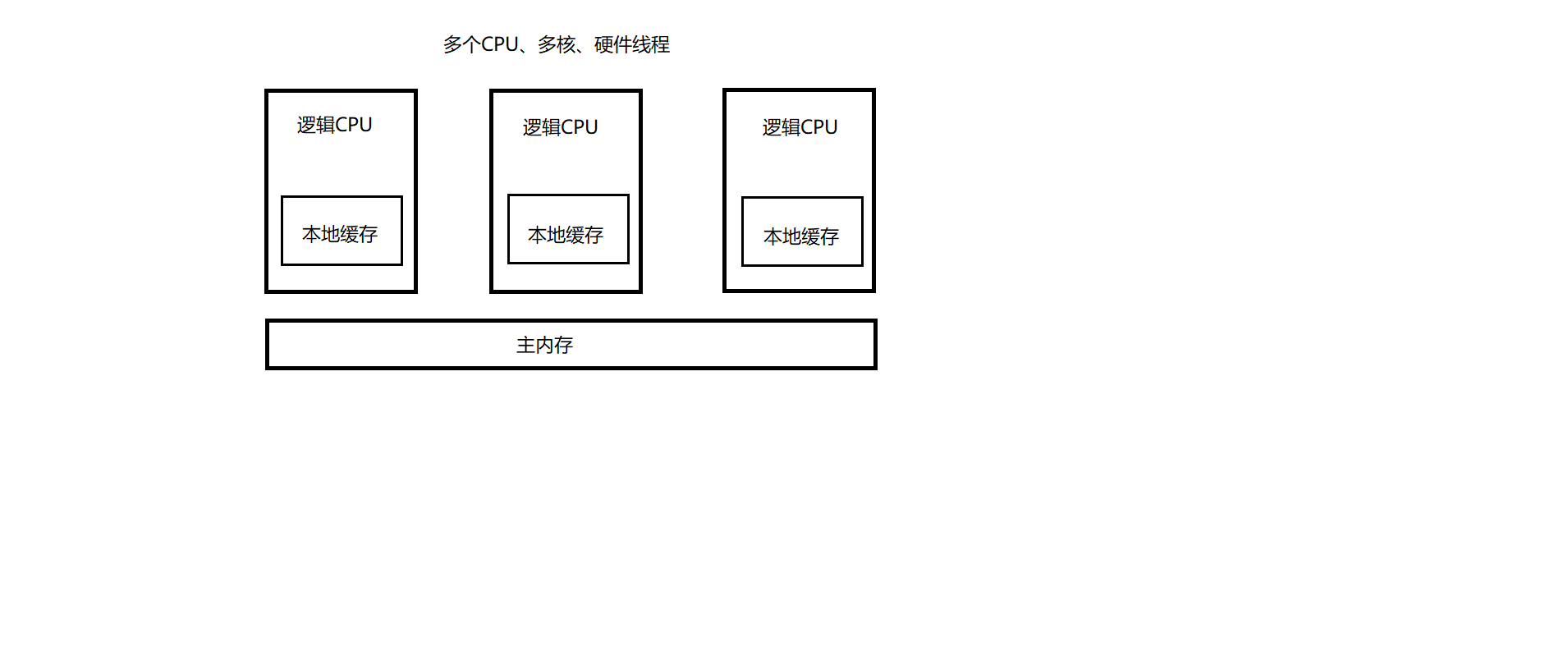
在硬件的架构里面(如上图),我们可以看到有多个逻辑CPU,每个逻辑CPU有自己的本地缓存。而本地缓存和主内存之间不是实时同步的,这种情况也会出现内存不一致的情况(内存可见性的问题)。
那么对于Java来讲,在Java的多线程模型里(如下图)。每个线程都会有自己的线程本地缓存以及共享内存,线程本地缓存和共享内存之间也是异步方式去处理的,这种情况也会出现内存不一致的情况(内存可见性的问题)。

重排序与内存可见性的关系
在多线程共同工作的场景下,我们有两个线程一个放到core0里执行,另一个放到core1里执行,我们希望core0里的线程在写数据的时候先写到共享内存(L3)中,然后core1里的线程去共享内存(L3)中读取core0里的线程写好的数据。
由于两个线程是同步执行的,并且buffer和内存(L1)之间是通过异步的方式去写入数据。那么就可能会出现这种情况,core1里面的线程去共享内存(L3)中读取数据时core0里的线程还没有将数据写入到共享内存(L3)中。这就是重排序的问题。因为我们希望的是core0里的线程先将数据写入到共享内存(L3)中去,然后core1里的线程去读取。
通俗的理解就是:
虽然你core0里的线程运行完了,但是数据并没有同步到L3(共享内存)中,但对于core1里的线程来说,就好比你还没运行结束我就开始去读取数据。(后操作的线程在先操作的线程前面执行完成)。
Store Buffer的延迟写入这种级别是重排序的一种,我们称之为内存重排序(Memory Ordering),因为这个问题是由于内存同步的问题产生的。
除此之外,还有其他类别的的重排序问题:
- 编译器重排序
对于没有先后依赖关系的语句,编译器可以重新调整语句的执行顺序(当我们编译代码时,编译器会对我们的代码进行优化,它会将这些没有先后依赖关系的语句重新排序,重新调整执行顺序达到提高我们代码的效率的目的)。
- CPU指令重排序
在指令级别,让没有依赖关系的多条指令并行(所有的代码最终都会变为机器码去执行,变为一条条指令交由CPU去执行,如果指令之间没有依赖关系那么这些指令就可以并行执行,从而达到提升效率的目的)。
- CPU内存重排序
CPU有自己的缓存,指令的执行顺序和写入主内存的顺序完全不一致。
其中CPU的内存重排序是造成“内存可见性”的主要原因,如下案例:
有两个线程,线程1 和 线程2
线程1:x = 1, a = y
线程2: y = 1, b = x
假设x、y是两个全局变量,初始的时候, x = 0, y = 0。请问,这两个线程执行完毕之后,a、b的正确结果应该是什么?
很显然线程1和线程2的执行顺序是不确定的,可能顺序执行,也可能交叉执行,最终正确的结果可能是:
a=0, b=1
a=1, b=0
a=1, b=1
如果两个线程的指令没有重排序,执行的顺序就是代码的顺序,但是仍然可能出现a=0,b=0。原因是线程1先执行x=1,后执行a=y,但此时x=1还在自己的Store Buffer里面,没有及时写入主内存中。所以,线程2看到的还是0。线程2的道理与此相同。
虽然线程1觉得自己是按照代码顺序正常执行的,但是在线程2看来,a=y和x=1顺序是颠倒的。指令没有重排序,是写入内存的操作被延迟了,也就是内存被重排序了,这就造成了内存可见性的问题。
内存屏障(Memory Barrier)
内存屏障是很底层的概念,对于java者来说,一般会用volatile关键字就够了。
-
概念:为了禁止编译器重排序和CPU重排序,在编译器和CPU层面都有对应的指令,也就是 内存屏障 。这也正是JMM和happen-before规则的底层实现原理。
-
认识:编译器的内存屏障,发挥着什么作用呢?它只是为了告诉编译器不要对指令进行重排序,当编译完成后,这种内存屏障就消失了,CPU并不会感知到编译器中内存屏障的存在。
-
进一步认识:
-
CPU的内存屏障是CPU提供的指令,可以由开发者显示调用。
-
分类:可以把基本的CPU内存屏障分为四种(JDK8以后在unsafe类中提供了三个内存屏障函数)
-
LoadLoad:禁止读和读的重排序
-
StoreStroe:禁止写和写的重排序
-
LoadStore:禁止写和读的重排序
-
StoredLoad:禁止写和读的重排序
-
下面是JDK11的源码,Unsafe类中的三个函数,根据代码我们可以看到
-
loadFence = LoadLoad+LoadStore
-
storeFence = Storestore+LoadStore
-
fullFence = loadFence + storeFence +StoreLoad
@ForceInline
public void loadFence() {
theInternalUnsafe.loadFence();
}
/**
* Ensures that loads and stores before the fence will not be reordered with
* stores after the fence; a "StoreStore plus LoadStore barrier".
*
* Corresponds to C11 atomic_thread_fence(memory_order_release)
* (a "release fence").
*
* A pure StoreStore fence is not provided, since the addition of LoadStore
* is almost always desired, and most current hardware instructions that
* provide a StoreStore barrier also provide a LoadStore barrier for free.
* @since 1.8
*/
@ForceInline
public void storeFence() {
theInternalUnsafe.storeFence();
}
/**
* Ensures that loads and stores before the fence will not be reordered
* with loads and stores after the fence. Implies the effects of both
* loadFence() and storeFence(), and in addition, the effect of a StoreLoad
* barrier.
*
* Corresponds to C11 atomic_thread_fence(memory_order_seq_cst).
* @since 1.8
*/
@ForceInline
public void fullFence() {
theInternalUnsafe.fullFence();
}
as-if-serial语义
我们了解了很多重排序,那么重排序的原则是什么?什么场景下可以重排序?什么场景下不能重排序呢?
- 单线程程序的重排序规则
无论什么语言,站在编译器和CPU的角度来说,不管怎么排序,单线程程序的执行结果不能改变,这就是单线程程序的重排序规则。
可以这么理解,只要操作之间没有数据依赖性,编译器和CPU都可以任意排序,因为执行结果不会改变,代码看起来就像是完全串行的一行行从头执行到尾,这就是as-if-serial语义。对于单线程程序来说,编译器和CPU可能做了重排序,但是开发者感觉不到,也不存在内存可见性问题。
- 多线程的重排序规则
编译器和CPU的这一行为对于单线程程序没有影响,但对多线程程序却有影响。对于多线程来说,线程之间的数据依赖性太复杂,编译器和CPU没有办法完全理解这种依赖性并据此做出最合理的优化。
编译器和CPU只能保证每个 线程的as-if-serial语义 。线程之间的数据依赖和相互影响需要编译器和CPU的上层确定。上层要告知编译器和CPU在多线程场景下什么时候可以重排序,什么时候不能重排序。
happen-before
- 什么是happen-before
使用happen-before描述两个操作之间的内存可见性
java内存模型(JMM)是一套规范,在多线程中,一方面要让编译器和CPU可以灵活地重排序;另一方面,要对开发者做一些承诺,明确告知开发者不需要感知什么样的重排序,需要感知什么样的重排序。然后,根据需要决定这种重排序对程序是否有影响。如果有影响,就需要开发者显示地通过volatile、sychronized等线程同步机制来禁止重排序。
- 关于happen-before
如果A happend-before B,意味着A的执行结果必须对B可见,也就是保证跨线程间的可见性。A happen before B 不代表A一定在B之前执行。因为,对于多线程程序而言,两个操作的执行顺序是不确定的。happen before 只是确保如果A在B之前执行,则A的执行结果必须对B可见。 定义了内存可见性的约束,也就定义了一系列重排序的约束 。
基于happen-before这种描述方法,JMM对开发者做出了一系列承诺:
1.单线程中的每个操作,happen before对应线程中任意后续操作(也就是as-if-serial语义保证)
2.对volatile变量的写入,happen before对应后续对这个变量的读取(先写变量 再读取)
3.对synchronized的解锁,happend before对应后续这个锁的加锁(先解锁再加锁)
- happen-before传递性
即 A happen before B , B happen before C 那么 A happen before C。如果一个变量不是volatile变量,当一个线程读取,一个线程写入时可能就会有问题。那岂不是说,在多线程程序中,我们要么加锁,要么必须把所以变量声明为volatile变量?显然这种方式不可能。
我们看下下面的案例:
public class Trial {
private int a = 0;
private volatile int c = 0;
public void set() {
// 操作1
a = 5;
// 操作2
c = 1;
}
public int get() {
// 操作3
int d=c;
// 操作4
return a;
}
}
假设线程Trial先调用了set,设置了a=5;之后另一个线程(B)调用了get,返回值一定是a=5。
分析下:
操作1 和操作2 是在同一个线程内存中执行的,操作1 happen before 操作2,同理,操作3 happend before 操作4。又因为c是volatile变量,对c的写入happen before对c的读取,所以操作2 happen before 操作3,这就利用了happen before的传递性,得到了,操作1 happen before 操作2,操作3 happen before 操作4,所以操作2 happen before 操作4,所以操作1的结果就一定对操作4可见。
synchronized也具有happen before语义。可以自己写个demo验证下。