SpringDataJPA+QueryDSL玩转态动条件/投影查询
在本文之前,本应当专门有一篇博客讲解SpringDataJPA使用自带的Specification+JpaSpecificationExecutor去说明如何玩条件查询,但是看到新奇、编码更简单易懂的技术总是会让人感到惊喜,而且QueryDSL对SpringDataJPA有着完美的支持。如果你没有使用过自带的Specification去做复杂查询,不用担心,本节分享的QueryDSL技术与SpringDataJPA自带支持的Specification没有关联。注意,本文内容一切都是基于SpringBoot1.x上构建的,如果还没有使用过SpringBoot的伙伴,请移步SpringBoot进行初步入门。
1、QueryDSL简介
如果说Hibernate等ORM是JPA的实现,而SpringDataJPA是对JPA使用的封装,那么QueryDSL可以是与SpringDataJPA有着同阶层的级别,它也是基于各种ORM之上的一个通用查询框架,使用它的API类库可以写出“Java代码的sql”,不用去手动接触sql语句,表达含义却如sql般准确。更重要的一点,它能够构建类型安全的查询,这比起JPA使用原生查询时有很大的不同,我们可以不必再对恶心的“Object[]”进行操作了。当然,我们可以SpringDataJPA + QueryDSL JPA联合使用,它们之间有着完美的相互支持,以达到更高效的编码。
2、QueryDSL JPA的使用
2.1 编写配置
2.1.1 pom.xml配置
在maven pom.xml的plugins标签中配置以下plugin:
<build>
<plugins>
<!--其他plugin...........-->
<!--因为是类型安全的,所以还需要加上Maven APT plugin,使用 APT 自动生成一些类:-->
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt-maven-plugin</artifactId>
<version>1.1.3</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>process</goal>
</goals>
<configuration>
<outputDirectory>target/generated-sources</outputDirectory>
<processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
继续在pom.xml 的dependencies中配置以下依赖:
<dependencies>
<!--SpringDataJPA-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--Web支持-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--QueryDSL支持-->
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<scope>provided</scope>
</dependency>
<!--QueryDSL支持-->
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
</dependency>
<!--mysql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.10</version>
<scope>provided</scope>
</dependency>
</dependencies>
2.1.2 application.properties配置
application.properties与之前几篇SpringDataJPA文章的application.yml配置作用是相同的,配置如下:
server.port=8888
server.context-path=/
server.tomcat.uri-encoding=utf-8
#数据源配置
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/springboot_test?characterEncoding=utf8
#数据库账号
spring.datasource.username=root
#数据库密码
spring.datasource.password=
spring.jpa.database=mysql
#是否展示sql
spring.jpa.show-sql=true
#是否自动生/更新成表,根据什么策略
spring.jpa.hibernate.ddl-auto=update
#命名策略,会将Java代码中的驼峰命名法映射到数据库中会变成下划线法
spring.jpa.hibernate.naming.strategy=org.hibernate.cfg.ImprovedNamingStrategy
2.1.3 JPAQueryFactory配置
使用QueryDSL的功能时,会依赖使用到JPAQueryFactory,而JPAQueryFactory在这里依赖使用EntityManager,所以在主类中做如下配置,使得Spring自动帮我们注入EntityManager与自动管理JPAQueryFactory:
@SpringBootApplication
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
//让Spring管理JPAQueryFactory
@Bean
public JPAQueryFactory jpaQueryFactory(EntityManager entityManager){
return new JPAQueryFactory(entityManager);
}
}
2.1.4 编写实体建模
在这里我们先介绍单表,待会儿介绍多表时我们在进行关联Entity的配置
@Data
@Entity
@Table(name = "t_user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer userId;
private String username;
private String password;
private String nickName;
private Date birthday;
private BigDecimal uIndex; //排序号
}
这个实体类非常简单,相信大家一定有所理解。没有使用过@Data注解,也可以不用,暂且就将他当做可以自动生成getXXX/setXXX方法的工具,如果你没有使用这个注解,也可以直接使用IDEA快捷键进行生成setXXX/getXXX。如果想了解这类注解,请前往lombok介绍
2.1.5 执行maven命令
然后在IDEA中选中你的MavenProject按钮,选中你的maven项目,双击compile按钮:
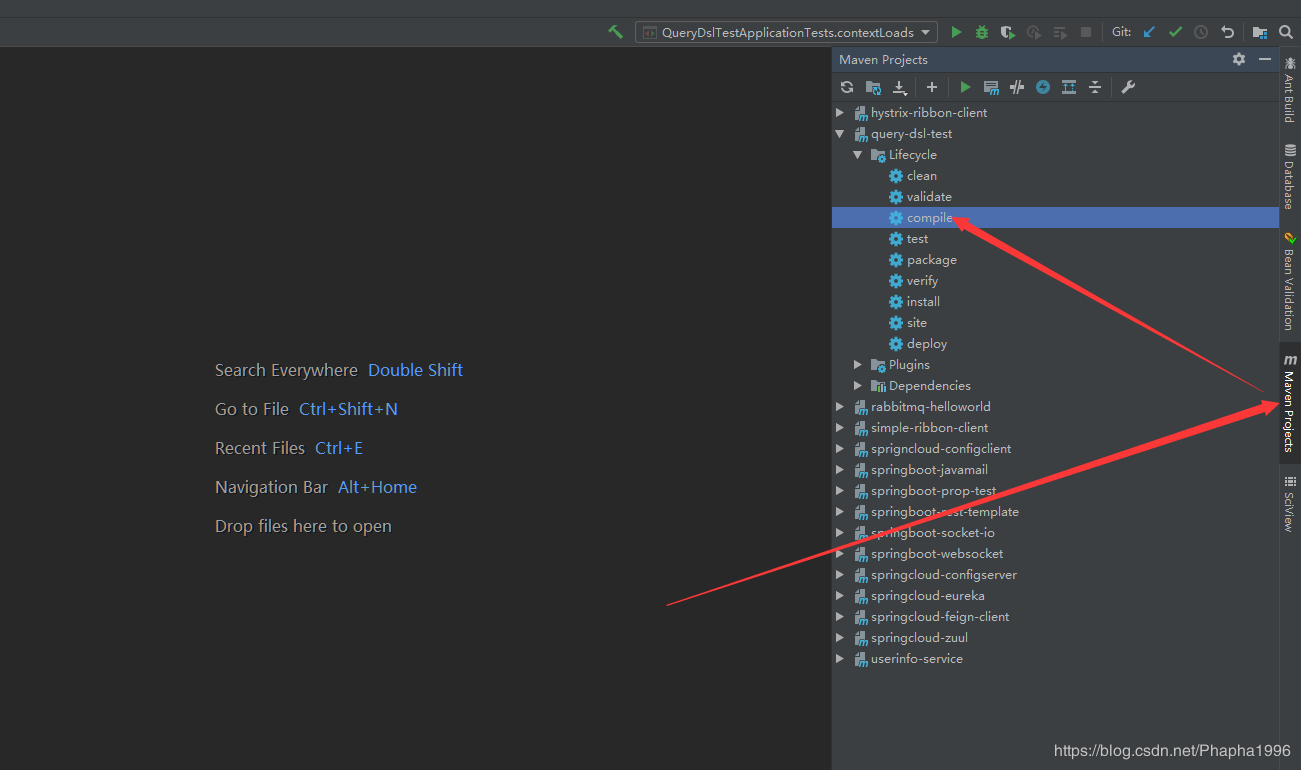
如果你的控制台提示你compile执行失败了,那么请留意一下你的maven路径是否在IDEA中进行了正确的配置。
以上步骤执行完毕后,会在你的target中自动生成了QUser类:
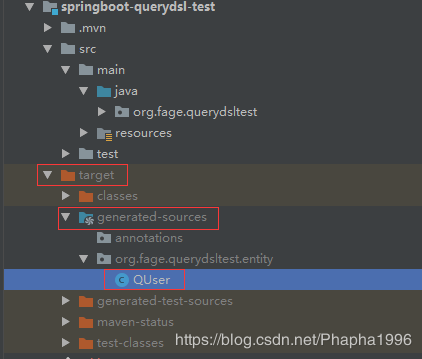
该类中的代码大致是这样的:
@Generated("com.querydsl.codegen.EntitySerializer")
public class QUser extends EntityPathBase<User> {
private static final long serialVersionUID = -646136422L;
public static final QUser user = new QUser("user");
public final DateTimePath<java.util.Date> birthday = createDateTime("birthday", java.util.Date.class);
public final StringPath nickName = createString("nickName");
public final StringPath password = createString("password");
public final NumberPath<java.math.BigDecimal> uIndex = createNumber("uIndex", java.math.BigDecimal.class);
public final NumberPath<Integer> userId = createNumber("userId", Integer.class);
public final StringPath username = createString("username");
public QUser(String variable) {
super(User.class, forVariable(variable));
}
public QUser(Path<? extends User> path) {
super(path.getType(), path.getMetadata());
}
public QUser(PathMetadata metadata) {
super(User.class, metadata);
}
}
一般每有一个实体Bean配置了@Entity被检测到之后,就会在target的子目录中自动生成一个Q+实体名称 的类,这个类对我们使用QueryDSL非常重要,正是因为它,我们才使得QueryDSL能够构建类型安全的查询。
2.2 使用
2.2.1 单表使用
在repository包中添加UserRepository,使用QueryDSL时可以完全不依赖使用QueryDslPredicateExecutor,但是为了展示与SpringDataJPA的联合使用,我们让repository继承这个接口,以便获得支持:
public interface UserRepository extends JpaRepository<User, Integer>, QueryDslPredicateExecutor<User> {
}
为了讲解部分字段映射查询,我们在bean包创建一个UserDTO类,该类只有User实体的部分字段:
@Data
@Builder
public class UserDTO {
private String userId;
private String username;
private String nickname;
private String birthday;
}
对于@Data与@Buider,都是lombok里的注解,能够帮我们生成get/set、toString方法,还能使用建造者模式去创建UserDTO,如果不会的同学也可以使用IDE生成get/set,想了解的同学可以进入lombok进行简单学习。
在service包中添加UserService,代码如下:
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Autowired
JPAQueryFactory jpaQueryFactory;
//////////////////////////以下展示使用原生的dsl/////////////////////
/**
* 根据用户名和密码查找(假定只能找出一条)
*
* @param username
* @param password
* @return
*/
public User findByUsernameAndPassword(String username, String password) {
QUser user = QUser.user;
return jpaQueryFactory
.selectFrom(user)
.where(
user.username.eq(username),
user.password.eq(password)
)
.fetchOne();
}
/**
* 查询所有的实体,根据uIndex字段排序
*
* @return
*/
public List<User> findAll() {
QUser user = QUser.user;
return jpaQueryFactory
.selectFrom(user)
.orderBy(
user.uIndex.asc()
)
.fetch();
}
/**
*分页查询所有的实体,根据uIndex字段排序
*
* @return
*/
public QueryResults<User> findAllPage(Pageable pageable) {
QUser user = QUser.user;
return jpaQueryFactory
.selectFrom(user)
.orderBy(
user.uIndex.asc()
)
.offset(pageable.getOffset()) //起始页
.limit(pageable.getPageSize()) //每页大小
.fetchResults(); //获取结果,该结果封装了实体集合、分页的信息,需要这些信息直接从该对象里面拿取即可
}
/**
* 根据起始日期与终止日期查询
* @param start
* @param end
* @return
*/
public List<User> findByBirthdayBetween(Date start, Date end){
QUser user = QUser.user;
return jpaQueryFactory
.selectFrom(user)
.where(
user.birthday.between(start, end)
)
.fetch();
}
/**
* 部分字段映射查询
* 投影为UserRes,lambda方式(灵活,类型可以在lambda中修改)
*
* @return
*/
public List<UserDTO> findAllUserDto(Pageable pageable) {
QUser user = QUser.user;
List<UserDTO> dtoList = jpaQueryFactory
.select(
user.username,
user.userId,
user.nickName,
user.birthday
)
.from(user)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch()
.stream()
.map(tuple -> UserDTO.builder()
.username(tuple.get(user.username))
.nickname(tuple.get(user.nickName))
.userId(tuple.get(user.userId).toString())
.birthday(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(tuple.get(user.birthday)))
.build()
)
.collect(Collectors.toList());
return dtoList;
}
/**
* 部分字段映射查询
* 投影为UserRes,自带的Projections方式,不够灵活,不能转换类型,但是可以使用as转换名字
*
* @return
*/
/*public List<UserDTO> findAllDto2() {
QUser user = QUser.user;
List<UserDTO> dtoList = jpaQueryFactory
.select(
Projections.bean(
UserDTO.class,
user.username,
user.userId,
user.nickName,
user.birthday
)
)
.from(user)
.fetch();
return dtoList;
}*/
//////////////////////////以下展示使用与SpringDataJPA整合的dsl/////////////////////
/**
* 根据昵称与用户名查询,并且根据uIndex排序
*
* @param nickName
* @return
*/
public List<User> findByNicknameAndUsername(String nickName, String username) {
QUser user = QUser.user;
List<User> users = (List<User>) userRepository.findAll(
user.nickName.eq(nickName)
.and(user.username.eq(username)),
user.uIndex.asc() //排序参数
);
return users;
}
/**
* 统计名字像likeName的记录数量
*
* @return
*/
public long countByNickNameLike(String likeName) {
QUser user = QUser.user;
return userRepository.count(
user.nickName.like("%" + likeName + "%")
);
}
//////////////////////////展示dsl动态查询////////////////////////////////
/**
* 所有条件动态分页查询
*
* @param username
* @param password
* @param nickName
* @param birthday
* @param uIndex
* @return
*/
public Page<User> findByUserProperties(Pageable pageable, String username, String password, String nickName, Date birthday, BigDecimal uIndex) {
QUser user = QUser.user;
//初始化组装条件(类似where 1=1)
Predicate predicate = user.isNotNull().or(user.isNull());
//执行动态条件拼装
predicate = username == null ? predicate : ExpressionUtils.and(predicate,user.username.eq(username));
predicate = password == null ? predicate : ExpressionUtils.and(predicate,user.password.eq(password));
predicate = nickName == null ? predicate : ExpressionUtils.and(predicate,user.nickName.eq(username));
predicate = birthday == null ? predicate : ExpressionUtils.and(predicate,user.birthday.eq(birthday));
predicate = uIndex == null ? predicate : ExpressionUtils.and(predicate,user.uIndex.eq(uIndex));
Page<User> page = userRepository.findAll(predicate, pageable);
return page;
}
/**
* 动态条件排序、分组查询
* @param username
* @param password
* @param nickName
* @param birthday
* @param uIndex
* @return
*/
public List<User> findByUserPropertiesGroupByUIndex(String username, String password, String nickName, Date birthday, BigDecimal uIndex) {
QUser user = QUser.user;
//初始化组装条件(类似where 1=1)
Predicate predicate = user.isNotNull().or(user.isNull());
//执行动态条件拼装
predicate = username == null ? predicate : ExpressionUtils.and(predicate, user.username.eq(username));
predicate = password == null ? predicate : ExpressionUtils.and(predicate, user.password.eq(password));
predicate = nickName == null ? predicate : ExpressionUtils.and(predicate, user.nickName.eq(username));
predicate = birthday == null ? predicate : ExpressionUtils.and(predicate, user.birthday.eq(birthday));
predicate = uIndex == null ? predicate : ExpressionUtils.and(predicate, user.uIndex.eq(uIndex));
//执行拼装好的条件并根据userId排序,根据uIndex分组
List<User> list = jpaQueryFactory
.selectFrom(user)
.where(predicate) //执行条件
.orderBy(user.userId.asc()) //执行排序
.groupBy(user.uIndex) //执行分组
.having(user.uIndex.longValue().max().gt(7))//uIndex最大值小于7
.fetch();
//封装成Page返回
return list;
}
}
代码有点多,解释一波。
a 、第一个方法是根据用户名与密码进行查询,QUser中有一个静态user属性,直接生成QUser的实例,QueryDSL都是围绕着这个QXxx来进行操作的。代码很直观,selectFrom是select方法与from方法的合并,这里为了方便就不分开写了,where中可以收可变参数Predicate,由于Predicate是一个接口,由user.username.eq或者user.uIndex.gt等等方法返回的都是BooleanExpression或者XXXExpression,这些XXXExpression都是Predicate的实现,故直接传入,让QueryDSL在内部做处理,其实Predicate也是实现了Expression接口,大家如果有兴趣可以自行跟踪源码研究。
b 、第二个方法也相当的直观,跟sql的字面意思几乎一模一样。
c 、第三个方法是第二个方法的排序写法,主要用到了offerset、limit方法,根据传入的pageable参数进行分页,最后返回的结果是一个QuerResults类型的返回值,该返回值对象简单的封装了一些分页的参数与返回的实体集,然调用者自己根据需求去取出使用。
d 、第四个方法展示了日期查询,也相当的直观,大家尝试了就知道了,主要使用到了between方法。
e 、第五个方法是比较重要的方法,这个方法展示了如何进行部分字段的映射查询,这个方法的目的是只查询uerrname、userId、nickname、birthday四个字段,然后封装到UserDTO中,最后返回。其中,由于select与from拆分了以后返回的泛型类型就是Tuple类型(Tuple是一个接口,它可以根据tuple.get(QUser.username)的方式获取User.username的真实值,暂时将他理解为一个类型安全的Map就行),根据pageable参数做了分页处理,fetch之后就返回了一个List对象。从fetch()方法之后,使用到了Stream,紧接着使用Java8的高阶函数map,这个map函数的作用是将List中的Tuple元素依次转换成List中的UserDTO元素,在这个过程中我们还可以做bean的属性类型转换,将User的Date、Integer类型都转换成String类型。最后,通过collect结束stream,返回一个我们需要的List。
f 、第六个方法与第五个方法的效果相同,使用QueryDSL的Projections实现。但是有一点,当User实体的属性类型与UserDTO中的属性类型不相同时,不方便转换。除了属性类型相同时转换方便以外,还是建议使用map函数进行操作。
g 、第七、第八个方法展示了QueryDSL与SpringDataJPA的联合使用,由于我们的UserRepository继承了QueryDslPredicateExecutor,所以获得了联合使用的支持。来看一看QueryDslPredicateExcutor接口的源码:
public interface QueryDslPredicateExecutor<T> {
T findOne(Predicate var1);
Iterable<T> findAll(Predicate var1);
Iterable<T> findAll(Predicate var1, Sort var2);
Iterable<T> findAll(Predicate var1, OrderSpecifier... var2);
Iterable<T> findAll(OrderSpecifier... var1);
Page<T> findAll(Predicate var1, Pageable var2);
long count(Predicate var1);
boolean exists(Predicate var1);
}
这里面的方法大多数都是可以传入Predicate类型的参数,说明还是围绕着QUser来进行操作的,如传入quser.username.eq(“123”)的方式,操作都非常简单。以下是部分源码,请看:
/*
* Copyright 2008-2017 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.springframework.data.jpa.repository.support;
import java.io.Serializable;
import java.util.List;
import java.util.Map.Entry;
import javax.persistence.EntityManager;
import javax.persistence.LockModeType;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.querydsl.EntityPathResolver;
import org.springframework.data.querydsl.QSort;
import org.springframework.data.querydsl.QueryDslPredicateExecutor;
import org.springframework.data.querydsl.SimpleEntityPathResolver;
import org.springframework.data.repository.support.PageableExecutionUtils;
import org.springframework.data.repository.support.PageableExecutionUtils.TotalSupplier;
import com.querydsl.core.types.EntityPath;
import com.querydsl.core.types.OrderSpecifier;
import com.querydsl.core.types.Predicate;
import com.querydsl.core.types.dsl.PathBuilder;
import com.querydsl.jpa.JPQLQuery;
import com.querydsl.jpa.impl.AbstractJPAQuery;
/**
* QueryDsl specific extension of {@link SimpleJpaRepository} which adds implementation for
* {@link QueryDslPredicateExecutor}.
*
* @author Oliver Gierke
* @author Thomas Darimont
* @author Mark Paluch
* @author Jocelyn Ntakpe
* @author Christoph Strobl
*/
public class QueryDslJpaRepository<T, ID extends Serializable> extends SimpleJpaRepository<T, ID>
implements QueryDslPredicateExecutor<T> {
private static final EntityPathResolver DEFAULT_ENTITY_PATH_RESOLVER = SimpleEntityPathResolver.INSTANCE;
private final EntityPath<T> path;
private final PathBuilder<T> builder;
private final Querydsl querydsl;
/**
* Creates a new {@link QueryDslJpaRepository} from the given domain class and {@link EntityManager}. This will use
* the {@link SimpleEntityPathResolver} to translate the given domain class into an {@link EntityPath}.
*
* @param entityInformation must not be {@literal null}.
* @param entityManager must not be {@literal null}.
*/
public QueryDslJpaRepository(JpaEntityInformation<T, ID> entityInformation, EntityManager entityManager) {
this(entityInformation, entityManager, DEFAULT_ENTITY_PATH_RESOLVER);
}
...............
............
至于源码,感兴趣的同学可以自行跟踪研究。
h 、最后,我们的杀手锏来了,JPA对动态条件拼接查询支持一向都不太灵活,如果在mybatis中,我们使用if标签可以很容易的实现动态查询,但是在JPA中,就没有那么方便了。SpringDataJPA给我们提供了Specification+JpaSpecificationExecutor帮我们解决,但是,在需要编写某些复杂的动态条件拼接、分组之后又动态拼接的复杂查询,可能就显得力不从心了,这个时候可能需要直接对entityManager操作,然后对sql进行拼接,请看以下 老代码是怎么写的 :
//自定义动态报表原生sql查询
//只要isSelect不为空,那么就执行条件查询:前端自行根据返回值判断是否已经选题(大于0就是选了题的)
public Page<StudentToAdminVO> findAllStudentToAdminVOPage(Pageable pageable, String majorId, Boolean isSelect, Boolean isSelectSuccess) {
//设置条件
StringBuffer where = new StringBuffer(" where 1=1 ");
StringBuffer having = new StringBuffer(" having 1=1");
if(!StringUtils.isEmpty(majorId)){
where.append(" and s.major_id=:majorId ");
}
if(isSelect!=null){
//是否选题了,只需要看查出的这个数是否大于零即可
if(isSelect)
having.append(" and count(se.id)>0 ");
else
having.append(" and count(se.id)=0 ");
}
if(isSelectSuccess != null){
if(isSelectSuccess)
having.append(" and max(se.is_select)>0");
else
having.append(" and (max(se.is_select) is null or max(se.is_select)<=0)");
}
//主体sql
String sql = "select s.id, s.username, s.nickname, s.sclass, m.name majorName, count(se.id) as choose, max(se.is_select) as selectSuccess from student s"
+ " left join selection se on s.id=se.student_id "
+ " left join major m on m.id=s.major_id "
+ where
+ " group by s.id"
+ having;
String countSql = null;
//计算总记录数sql
if(isSelect!=null){
countSql = "select count(*) from student s "
+ where
+ " and s.id in(select ss.id FROM student ss left join selection se on se.student_id=ss.id GROUP BY ss.id "
+ having
+ " )";
}else{
countSql = "select count(*) from student s " + where;
}
//创建原生查询
Query query = em.createNativeQuery(sql);
Query countQuery = em.createNativeQuery(countSql);
if(!StringUtils.isEmpty(majorId)){
query.setParameter("majorId", majorId);
countQuery.setParameter("majorId", majorId);
}
int total = Integer.valueOf(countQuery.getSingleResult().toString());
// pageable.getPageNumber()==0 ? pageable.getOffset() : pageable.getOffset()-5
if(pageable!=null){
query.setFirstResult(pageable.getOffset());
query.setMaxResults(pageable.getPageSize());
}
//对象映射
query.unwrap(SQLQuery.class)
.addScalar("id", StandardBasicTypes.STRING)
.addScalar("username", StandardBasicTypes.STRING)
.addScalar("nickname", StandardBasicTypes.STRING)
.addScalar("sclass", StandardBasicTypes.STRING)
.addScalar("majorName", StandardBasicTypes.STRING)
.addScalar("choose", StandardBasicTypes.INTEGER)
.addScalar("selectSuccess", StandardBasicTypes.INTEGER)
.setResultTransformer(Transformers.aliasToBean(StudentToAdminVO.class));
return new PageImpl<StudentToAdminVO>(query.getResultList(), pageable, total);
}
我们再来看一个对JPQL拼接的例子:
/**
* 动态查询
* @param pageable
* @param isSelect 是否确选(只要非空,都相当于加了条件)
* @param titleLike 根据title模糊查询
* @param teacherId 根据老师的id查询
* @return
*/
Page<SubjectToTeacherVO> findAllSubjectToTeacherVO(Pageable pageable, Boolean isSelect, String titleLike,
String teacherId, String majorId, String studentId){
//条件组合
StringBuffer where = new StringBuffer(" where 1=1 ");
StringBuffer having = new StringBuffer();
if(isSelect != null){
if(isSelect)
having.append(" having max(se.isSelection)>0 ");
else
having.append(" having ((max(se.isSelection) is null) or max(se.isSelection)<=0) ");
}
if(!StringUtils.isEmpty(titleLike))
where.append(" and su.title like :titleLike");
if(!StringUtils.isEmpty(teacherId))
where.append(" and su.teacher.id=:teacherId");
if(!StringUtils.isEmpty(majorId))
where.append(" and su.major.id=:majorId");
if(!StringUtils.isEmpty(studentId)){
where.append(" and su.major.id=(select stu.major.id from Student stu where stu.id=:studentId)");
}
//主jpql 由于不能使用 if(exp1,rsul1,rsul2)只能用case when exp1 then rsul1 else rsul2 end
String jpql = "select new cn.edu.glut.vo.SubjectToTeacherVO(su.id, su.title, cast(count(se.id) as int) as guysNum, max(se.isSelection) as choose, "
+ " (select ss.nickname from Selection as sel left join sel.student as ss where sel.subject.id=su.id and sel.isSelection=1) as stuName, "
+ " (select t.nickname from Teacher t where t.id=su.teacher.id) as teacherName, "
+ " ma.id as majorId, ma.name as majorName) "
+ " from Subject as su left join su.selections as se"
+ " left join su.major as ma "
+ where
+ " group by su.id "
+ having;
String countJpql = null;
if(isSelect != null)
countJpql = "select count(*) from Subject su left join su.selections as se left join se.student as s"
+ where
+ " and su.id in(select s.id from Subject s left join s.selections se group by s.id "
+ having
+ " )";
else
countJpql = "select count(*) from Subject su left join su.selections as se left join se.student as s" + where;
Query query = em.createQuery(jpql, SubjectToTeacherVO.class);
Query countQuery = em.createQuery(countJpql);
// pageable.getPageNumber()==0 ? pageable.getOffset() : pageable.getOffset()-5
if(null != pageable){
query.setFirstResult(pageable.getOffset());
query.setMaxResults(pageable.getPageSize());
}
if(!StringUtils.isEmpty(titleLike)){
query.setParameter("titleLike", "%"+titleLike+"%");
countQuery.setParameter("titleLike", "%"+titleLike+"%");
}
if(!StringUtils.isEmpty(teacherId)){
query.setParameter("teacherId", teacherId);
countQuery.setParameter("teacherId", teacherId);
}
if(!StringUtils.isEmpty(majorId)){
query.setParameter("majorId", majorId);
countQuery.setParameter("majorId", majorId);
}
if(!StringUtils.isEmpty(studentId)){
query.setParameter("studentId", studentId);
countQuery.setParameter("studentId", studentId);
}
List<SubjectToTeacherVO> voList = query.getResultList();
return new PageImpl<SubjectToTeacherVO>(voList, pageable, Integer.valueOf(countQuery.getSingleResult().toString()));
}
说恶心一点都不过分…不知道小伙伴们觉得如何,反正我是忍不了了…
我们UserService中的最后两个方法就是展示如何做动态查询的,第一个方法结合了与SpringDataJPA整合QueryDSL的findAll来实现,第二个方法使用QueryDSL本身的API进行实现,其中Page是Spring自身的的。第一行user.isNotNull.or(user.isNull())可以做到类似where 1=1的效果以便于后面进行的拼接,当然,主键是不能为空的,所以此处也可以只写user.isNotNull()也可以。紧接着是一串的三目运算符表达式,以第一行三目表达式为例,表达意义在于:如果用户名为空,就返回定义好的predicate;如果不为空,就使用ExpressionUtils的and方法将username作为条件进行组合,ExpressionUtils的and方法返回值也是一个Predicate。下面的几条三目运算符与第一条是类似的。最后使用findAll方法传入分页参数与条件参数predicate,相比起上面头疼的自己拼接,是不是简洁了很多?
最后一个方法展示的是如果有分组条件时进行的查询,相信大家就字面意思理解也能知道大概的意思了,前半部分代码是相同的,groupby之后需要插入条件是要用到having的。就与sql的规范一样,如果对分组与having还不了解,希望大家多多google哦。
2.2.2 多表使用
对于多表使用,大致与单表类似。我们先创建一个一对多的关系,一个部门对应有多个用户,创建Department实体:
@Data
@Entity
@Table(name = "t_department")
public class Department {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer deptId; //部门id
private String deptName; //部门名称
private Date createDate; //创建时间
}
在User实体需要稍稍修改,User实体中添加department建模:
@Data
@Entity
@Table(name = "t_user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer userId;
private String username;
private String password;
private String nickName;
private Date birthday;
private BigDecimal uIndex; //排序号
//一对多映射
@ManyToOne(cascade = CascadeType.MERGE, fetch = FetchType.EAGER)
@JoinColumn(name = "department_id")
private Department department; //部门实体
}
我们假设有一个这样的需求,前端需要展示根据部门deptId来查询用户的基础信息,在展示用户基础信息的同时需要展示该用户所属的部门名称以及该部门创建的时间。那么,我们创建一个这样的DTO来满足前端的需求:
@Data
@Builder
public class UserDeptDTO {
//用户基础信息
private String username; //用户名
private String nickname; //昵称
private String birthday; //用户生日
//用户的部门信息
private String deptName; //用户所属部门
private String deptBirth; //部门创建的时间
}
大家一定想到了使用部分字段映射的投影查询,接下来我们在UserService中添加如下代码:
/**
* 根据部门的id查询用户的基本信息+用户所属部门信息,并且使用UserDeptDTO进行封装返回给前端展示
* @param departmentId
* @return
*/
public List<UserDeptDTO> findByDepatmentIdDTO(int departmentId) {
QUser user = QUser.user;
QDepartment department = QDepartment.department;
//直接返回
return jpaQueryFactory
//投影只去部分字段
.select(
user.username,
user.nickName,
user.birthday,
department.deptName,
department.createDate
)
.from(user)
//联合查询
.join(user.department, department)
.where(department.deptId.eq(departmentId))
.fetch()
//lambda开始
.stream()
.map(tuple ->
//需要做类型转换,所以使用map函数非常适合
UserDeptDTO.builder()
.username(tuple.get(user.username))
.nickname(tuple.get(user.nickName))
.birthday(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(tuple.get(user.birthday)))
.deptName(tuple.get(department.deptName))
.deptBirth(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(tuple.get(department.createDate)))
.build()
)
.collect(Collectors.toList());
}
select部分是选择需要查询的字段,leftjoin的第一个参数是用户所关联的部门,第二个参数可以当做该user.department别名来使用,往后看即可理解。where中只有一个很简单的条件,即根据部门的id来进行查询,最后使用stream来将Tuple转换成UserDeptDTO,中间在map函数中对一些属性的类型进行了转换。其他的关联操作与上述代码类似,对于orderBy、groupBy、聚合函数、分页操作的API都与单表的类似,只是where中的条件自己进行适配即可。
在应用开发中我们可能不会在代码中设置@ManyToOne、@ManyToMany这种类型的“强建模”,而是在随从的Entity中仅仅声明一个外键属性,比如User实体的下面代码,只是添加了一个departmentId:
@Data
@Entity
@Table(name = "t_user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer userId;
private String username;
private String password;
private String nickName;
private Date birthday;
private BigDecimal uIndex; //排序号
private Integer departmentId;
}
这时候我们的多表关联业务代码只需要稍作修改就可以:
/**
* 根据部门的id查询用户的基本信息+用户所属部门信息,并且使用UserDeptDTO进行封装返回给前端展示
*
* @param departmentId
* @return
*/
public List<UserDeptDTO> findByDepatmentIdDTO(int departmentId) {
QUser user = QUser.user;
QDepartment department = QDepartment.department;
//直接返回
return jpaQueryFactory
//投影只去部分字段
.select(
user.username,
user.nickName,
user.birthday,
department.deptName,
department.createDate
)
.from(user, department)
//联合查询
.where(
user.departmentId.eq(department.deptId).and(department.deptId.eq(departmentId))
)
.fetch()
//lambda开始
.stream()
.map(tuple ->
//需要做类型转换,所以使用map函数非常适合
UserDeptDTO.builder()
.username(tuple.get(user.username))
.nickname(tuple.get(user.nickName))
.birthday(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(tuple.get(user.birthday)))
.deptName(tuple.get(department.deptName))
.deptBirth(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(tuple.get(department.createDate)))
.build()
)
.collect(Collectors.toList());
}
我们在from中多加了department参数,在where中多加了一个user.department.eq(department.deptId)条件,与sql中的操作类似。为什么在这里不适用join…on…呢,原因是我们使用的是QueryDSL-JPA,QueryDSL对JPA支持是全面的,当然也有QueryDSL-SQL,但是配置起来会比较麻烦。如果大家想了解QueryDSL-SQL可以点击这里进行了解。
3 结语
使用SpringDataJPA能够解决我们大多数问题,但是在处理复杂条件、动态条件、投影查询时可能QueryDSL JPA更加直观,而且SpringDataJPA对QueryDSL有着非常好的支持,SpringDataJPA+QueryDSL在我眼里看来是天生一对,互相补漏。在使用一般查询、能够满足基础条件的查询我们使用SpringDataJPA更加简洁方便,当遇到复杂、投影、动态查询时我们可以考虑使用QueryDSL做开发。以上方案可以解决大多数持久层开发问题,当然,如果问题特别刁钻,还是不能满足你的需求,你也可以考虑直接操作HQL或者SQL。
今天的分享就到此结束了,小伙伴们如果有更好的建议,欢迎大家提出指正,但是请不要谩骂与辱骂,写一篇博客实属不易。